
or…Just When You Thought It Was Safe To Go Back Onto The Internet
This is the second part of a blog post looking at some particularly bad examples of digitisation in the world of family history research. In the first part I looked at some of the shortcomings of Findmypast’s Index To Death Duty Registers 1796-1903.
To my mind, when it comes to commercial digitisation projects, the main purpose of transcribing the data from historical records is to create a way into the documents themselves. Essentially, the transcript should be a finding aid, ideally, linked to digital images of the documents, thus allowing the user to work out for themselves what the particular entry is telling them. As a rule, I’m not too bothered about how accurate the actual transcription is. As anyone who has ever attempted the task will tell you, reading and interpreting large chunks of old handwriting with anything approaching 100% accuracy is a pipedream: there are simply too many instances when the handwriting is illegible, either due to the (lack of) skill of the original writer or because the document is badly damaged, soiled or faded.
Of course, the more accurate the transcription the better, but I always feel that as long as it’s of a reasonably good standard, a good, powerful, flexible search engine will get around most difficulties and enable us to find just about everything that we’re looking for. And if that fails, the ability to browse through the document, page-by-page, is a useful asset.
What’s more important is that the people behind the transcription and the digitisation project as a whole, have a good grasp of what it is they’re dealing with; that they understand the different types of document that make up the collection and how the format and content of those documents might change over time.
Unfortunately, Ancestry’s London, England, Freedom of the City Admission Papers, 1681-1930 database is a good example of a database over which those responsible for digitising the records appear to have had little or no intellectual control.

The original records are held by the London Metropolitan Archives and were digitised by Ancestry in 2010. It’s a truly remarkable collection of documents recording the admission of nearly 250,000 men (and some women) to the prestigious ‘Freedom’ of the City of London. Attaining the privileges that the Freedom granted you was essential for anyone who wished to trade within the City and the records created during the process can be enormously useful for anyone researching ancestors who lived and worked within the ‘Square Mile’.
The Admission Papers form one of several collections relating to the Freedom of the City. They are by far the most important (genealogically speaking) and the others are not available online. They are also a complex and disparate collection of records.
Essentially, there were three ways of becoming a Freeman of the City:
- by servitude (i.e. after completing an apprenticeship – usually of 7 years)
- by patrimony (i.e. as the legitimate child of a Freeman, born after their parent was admitted)
- by redemption or purchase (i.e. by paying a sum of money)
The collection of Admission Papers comprises records relating to all three types of admission – records which differ significantly in content. Across the three we can find a wide range of details being recorded, including the following:
- Name
- Date of birth
- Residence
- Occupation
- Father’s name
- Father’s residence
- Father’s occupation
- Date of father’s admission
- Master’s name
- Livery Company
- Date of apprenticeship
- Date of admission
- Means of admission
It’s not difficult to see how rich a source of genealogical data the records represent: plenty of names, relationships, dates and places – the bedrock of family history research.
Let’s have a look at how Ancestry has dealt with it all…
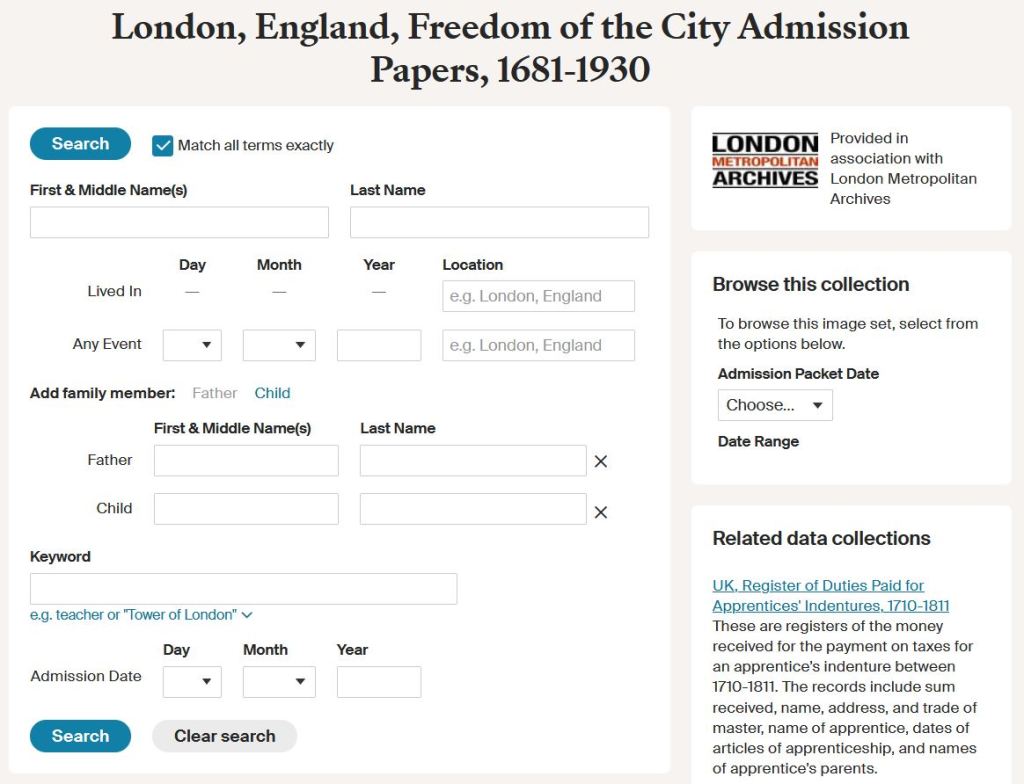
The search screen includes many of the standard Ancestry fields but when it comes to dates, the only two fields available are the ubiquitous ‘Any Event’ and the ‘custom’ Admission Date. The Father and Child fields are also available to us, as well as the always-useful ‘Keyword’ option.
The search results include the following pieces of data:
- Name
- Birth Date
- Admission Date
- Master
- Father
Let’s see what happens when we run a typical search.
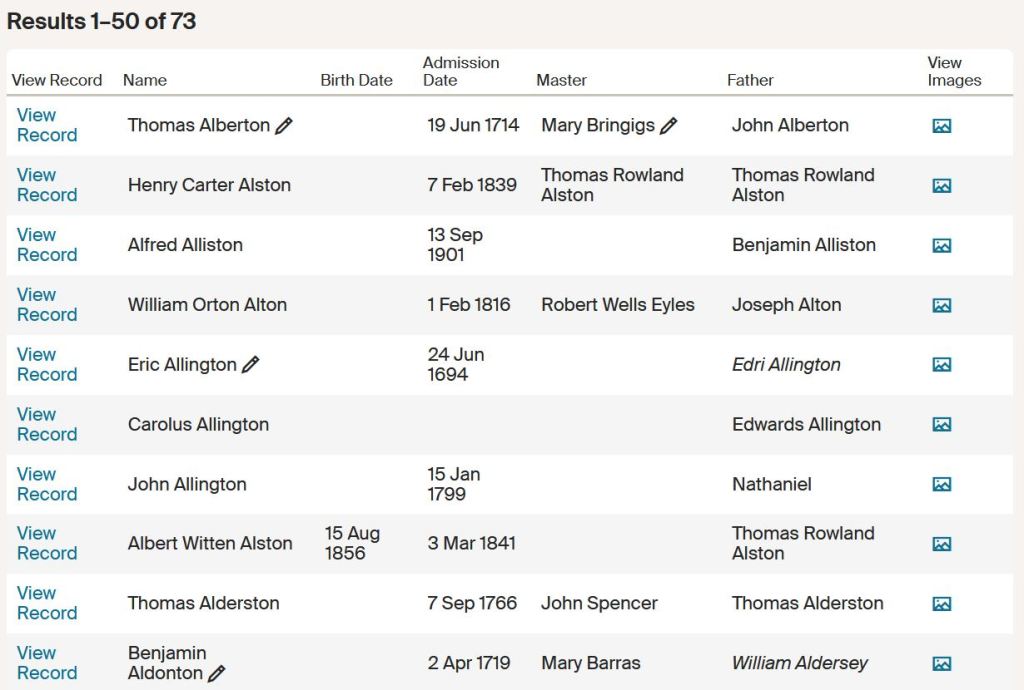
Search was for the surname Al*ton
A quick glance at the results page doesn’t exactly fill you with confidence! The significant number of ‘corrected entries and the disjointed nature of some of the data are sure signs that all is not well. And a deeper look reveals the true horror of it all…
After looking at each of the ten records and abstracting the relevant data, I was able to come up with an ‘improved’ results page, sticking to Ancestry’s choice of fields:

So, let’s have another look at the original Ancestry results. I’ve highlighted the fields which contain errors but perhaps it would have been easier to highlight those that don’t contain any. It is absolutely riddled with them!
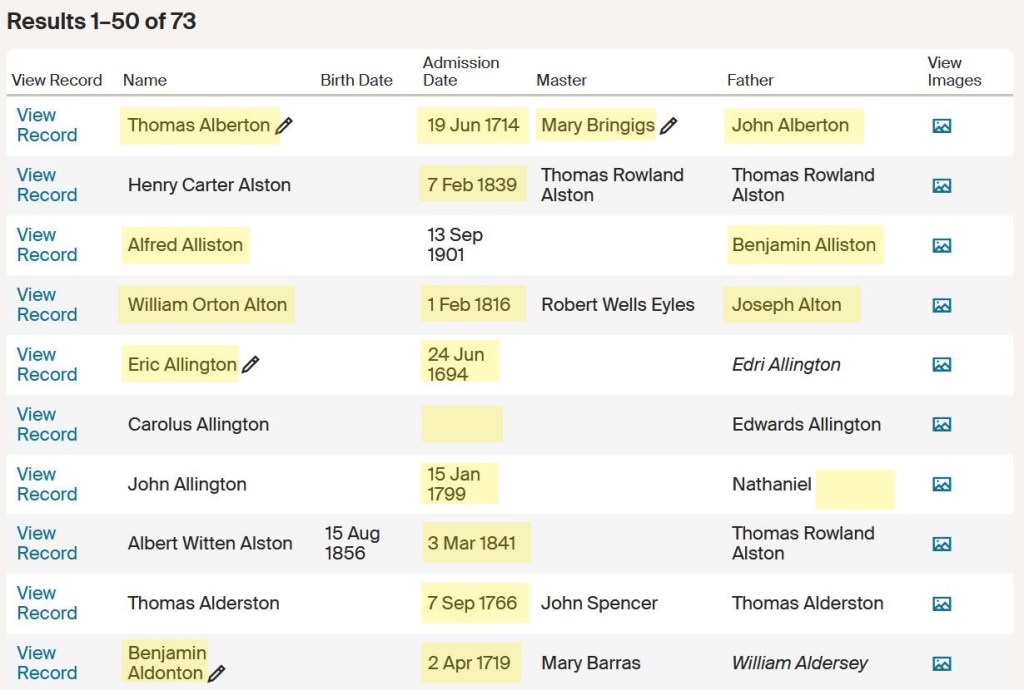
Data errors highlighted in yellow
As I mentioned earlier, I’m not that bothered about the odd transcription error here and there, and a few of the ones in this little sample are, admittedly, quite minor. Transcribing names where the original is in Latin is always going to be a challenge but (sorry to repeat myself but it needs to be said!) as the main purpose of an index like this should be to create a finding aid, it would seem like a sensible policy to ‘translate’ the names into English. So ‘Edri’ should really be Edward and Carolus should be Charles. At least it seems that Ancestry have treated these names as ‘variants’ of the English name so a search for ‘Charles Allington’ will find the entry for ‘Carolus’. Some of the data has already been corrected by other users so if we’re just looking at the names, it shouldn’t, in theory, be too difficult to find most of these entries.
But there’s something working against us here: and it’s the data in the field headed ‘Date of admission’. As you will see, eight of the ten dates in our sample are wrong (one of them suggests that the freeman in question was admitted 15 years before he was born!) and one of them has no data recorded at all. Nine of them are therefore ‘wrong’ – and the bad news is that this sample is representative of the whole database…
It’s clear to me that Ancestry have failed to understand the records here. Because in most cases, the date of admission isn’t actually recorded on the document itself: instead, it can be discerned from the handwritten reference (usually on the back of the document) and from the description of the bundle of documents (either a range of dates or a particular month). But this data hasn’t been captured by Ancestry.
The date that Ancestry have recorded as the date of admission, is actually, in most cases, the date of the apprenticeship, which is usually about ten years earlier than the date of admission – and the admission date can be significantly later. On average, the dates given here as the date of admission are 12.3 years out from the actual date.
Dates of birth are only rarely recorded so it seems strange to show this data in the results field. What would perhaps be more useful would be to record the date of apprenticeship. Well over half of those admitted had served apprenticeships and as most boys were apprenticed when they were 14 we can estimate their likely dates of birth from this information.
It would also be good to know where the apprentices were from, so the father’s residence would be a useful addition and it would be nice to include the name of the livery company (and to be able to search on this data!). So, if things were being done properly, we could have an index that looks something like this:

You might argue that a bad index is better than no index at all and I agree … to a point. But the problem is that by creating these indexes the websites involved have made it extremely unlikely that the records will ever be properly indexed by people who really understand the documents in question. And that’s a real shame…
© David Annal, Lifelines Research, 27 January 2022


Pingback: When Digitisation Goes Bad Part I: The Night Of The Living Death Duties | Lifelines Research